AI Bundesliga Tipps: Virtuelle Simulationen

Ladevorgang...
Stell dir vor, du könntest ein Bundesliga-Spiel nicht nur einmal sehen, sondern zehntausend Mal. Jedes Mal mit leicht unterschiedlichem Verlauf, anderen Toren, anderen Fehlern. Am Ende könntest du auswerten, wie oft welches Ergebnis eingetreten ist, und hättest damit eine ziemlich gute Vorstellung davon, was beim echten Spiel passieren könnte. Genau das machen Simulationsmodelle, die für KI-basierte Bundesliga-Tipps eingesetzt werden. Jedes Spiel wird tausendfach durchgerechnet, um dir perfekte AI Bundesliga Tipps zu liefern.
Die Idee klingt zunächst etwas abstrakt, ist aber im Kern sehr intuitiv. Statt zu sagen, dass Bayern München dieses Spiel wahrscheinlich gewinnt, lässt man den Computer das Spiel virtuell sehr oft durchspielen und zählt dann einfach, wie oft Bayern tatsächlich gewonnen hat. Wenn Bayern in siebentausend von zehntausend Simulationen als Sieger hervorgeht, kann man daraus eine Siegwahrscheinlichkeit von siebzig Prozent ableiten.
Dieser Artikel erklärt, wie Spielsimulationen für Bundesliga-Prognosen funktionieren, welche Methoden zum Einsatz kommen und wo die Grenzen dieser Herangehensweise liegen. Wer verstehen möchte, was hinter den Wahrscheinlichkeitsangaben bei KI-Tipps steckt, wird hier fündig.
Das Grundprinzip von Spielsimulationen
Bevor wir in die technischen Details einsteigen, ist es wichtig, das grundlegende Konzept zu verstehen. Eine Simulation ist im Kern nichts anderes als ein Modell, das versucht, die Realität nachzubilden. Im Falle eines Fußballspiels bedeutet das, die wesentlichen Aspekte des Spiels mathematisch zu beschreiben und dann wiederholt ablaufen zu lassen.
Ein einfaches Simulationsmodell könnte etwa so funktionieren: Basierend auf historischen Daten weiß man, dass Bayern München zu Hause durchschnittlich 2,3 Tore pro Spiel erzielt und 0,8 Tore kassiert. Der Gegner, sagen wir Union Berlin, erzielt auswärts durchschnittlich 1,1 Tore und kassiert 1,7. Diese Durchschnittswerte werden kombiniert und angepasst, um erwartete Torwerte für dieses spezielle Spiel zu erhalten.

Dann kommt der entscheidende Schritt: Die Simulation würfelt gewissermaßen aus, wie viele Tore jedes Team in diesem virtuellen Spiel erzielt. Das geschieht nicht mit einem echten Würfel, sondern mit mathematischen Verteilungen, die realistisches Verhalten abbilden. Der Prozess wird tausende Male wiederholt, und am Ende hat man eine Verteilung möglicher Ergebnisse.
Das klingt vielleicht überraschend simpel, und tatsächlich gibt es zwischen diesem Grundkonzept und ausgereiften Prognosemodellen einen weiten Weg. Aber das Prinzip bleibt dasselbe: Unsicherheit wird durch viele Wiederholungen in Wahrscheinlichkeiten übersetzt.
Die Monte-Carlo-Methode verständlich erklärt
Der Name Monte Carlo mag exotisch klingen, er kommt tatsächlich von dem bekannten Casino in Monaco. Die Methode wurde in den 1940er Jahren bei der Entwicklung der Atombombe erfunden und hat seitdem in unzähligen Bereichen Anwendung gefunden, von der Finanzwirtschaft über die Physik bis hin zum Sport.
Das Grundprinzip ist bemerkenswert einfach. Wenn du ein Problem hast, das zu komplex ist, um es direkt zu lösen, kannst du es stattdessen simulieren. Indem du viele zufällige Szenarien durchspielst und die Ergebnisse sammelst, näherst du dich der wahren Lösung an.
Im Fußballkontext funktioniert das so: Anstatt zu versuchen, das exakte Ergebnis eines Spiels vorherzusagen, was letztlich unmöglich ist, simuliert man viele mögliche Spielverläufe. Jede einzelne Simulation ist nur ein mögliches Szenario, aber in der Gesamtheit aller Simulationen zeigt sich ein statistisch belastbares Bild.
Ein konkretes Beispiel hilft beim Verständnis. Angenommen, wir möchten die Wahrscheinlichkeit berechnen, dass Borussia Dortmund in einem bestimmten Spiel mindestens zwei Tore erzielt. Ein direkter mathematischer Weg wäre komplex und würde viele Annahmen erfordern. Mit Monte Carlo geht es einfacher: Wir simulieren das Spiel zehntausend Mal und zählen, wie oft Dortmund mindestens zwei Tore geschossen hat. Wenn das in sechstausendfünfhundert Fällen passiert, liegt die Wahrscheinlichkeit bei etwa fünfundsechzig Prozent.
Der Charme dieser Methode liegt in ihrer Flexibilität. Man kann beliebig komplexe Bedingungen berücksichtigen, solange man sie in das Simulationsmodell einbauen kann. Wie wahrscheinlich ist es, dass Dortmund gewinnt, wenn sie nach der ersten Halbzeit zurückliegen? Auch das lässt sich simulieren.
Von einzelnen Spielen zu ganzen Saisons
Die Simulation einzelner Spiele ist nur der Anfang. Richtig interessant wird es, wenn man ganze Saisonen simuliert. Dabei werden nicht nur die einzelnen Partien durchgespielt, sondern auch ihre Abhängigkeiten berücksichtigt.

Eine Saisonsimulation beginnt mit dem aktuellen Stand der Liga, also den Punkten, Toren und der verbleibenden Spielpaarungen. Dann werden alle noch ausstehenden Spiele simuliert, und am Ende hat man einen möglichen Tabellenstand. Dieser Prozess wird tausende Male wiederholt, und aus den Ergebnissen lassen sich Wahrscheinlichkeiten ableiten.
Wie wahrscheinlich ist es, dass Bayern München Meister wird? Die Simulation gibt eine Antwort, indem sie zählt, wie oft Bayern am Ende der simulierten Saisons auf Platz eins landet. Wer hat die besten Chancen, den Abstieg zu vermeiden? Auch das ergibt sich aus der Verteilung der Tabellenplätze über alle Simulationen.
Besonders wertvoll sind Saisonsimulationen in der Rückrunde, wenn die Spielpläne bekannt sind und sich abzeichnet, welche Duelle entscheidend sein werden. Ein Team, das noch gegen die direkten Konkurrenten spielen muss, hat ein anderes Risikoprofil als eines, dessen schwere Gegner bereits hinter ihm liegen.
Die Ergebnisse solcher Simulationen werden oft in Form von Prozentangaben präsentiert. Schau dir an, wie sich diese Berechnungen in unseren Prognosen für die Saison 2026 widerspiegeln. Bayern hat eine Meisterschaftswahrscheinlichkeit von fünfundachtzig Prozent, Dortmund von zwölf Prozent, Leipzig von drei Prozent. Diese Zahlen wirken sehr konkret, aber man sollte im Hinterkopf behalten, dass sie auf Modellen basieren, die zwangsläufig vereinfachen. Die wahre Unsicherheit ist immer größer, als die Zahlen suggerieren.
Wie viele Simulationen braucht man?
Eine natürliche Frage ist, wie oft man ein Spiel oder eine Saison simulieren muss, um verlässliche Ergebnisse zu bekommen. Die Antwort hängt davon ab, welche Genauigkeit man anstrebt und welche Wahrscheinlichkeiten man untersucht.
Für grobe Schätzungen reichen oft schon tausend Simulationen. Wenn Bayern in achthundert von tausend Simulationen gewinnt, kann man recht sicher sagen, dass ihre Siegwahrscheinlichkeit bei etwa achtzig Prozent liegt. Der statistische Fehler beträgt bei tausend Durchläufen ungefähr drei Prozent, also irgendwo zwischen siebenundsiebzig und dreiundachtzig Prozent.
Für genauere Aussagen oder seltene Ereignisse braucht man mehr Simulationen. Wenn man wissen möchte, wie wahrscheinlich ein exaktes Ergebnis wie ein Dreizuzwei ist, reichen tausend Durchläufe oft nicht aus. Solche Ereignisse treten vielleicht in fünf Prozent der Fälle ein, also nur fünfzig Mal bei tausend Simulationen. Um die Wahrscheinlichkeit präzise zu schätzen, wären zehntausend oder sogar hunderttausend Durchläufe besser.
Professionelle Prognosemodelle nutzen typischerweise zehntausend bis hunderttausend Simulationen pro Vorhersage. Bei moderner Rechenleistung ist das kein Problem, selbst auf einem handelsüblichen Computer dauert das nur Sekunden. Der Aufwand lohnt sich, weil die Ergebnisse dadurch statistisch stabiler werden.
Ein praktisches Kriterium für ausreichend viele Simulationen ist die Konvergenz. Wenn man die Simulation mehrmals unabhängig durchführt und dabei jedes Mal ähnliche Ergebnisse erhält, hat man wahrscheinlich genug Durchläufe gemacht. Weichen die Ergebnisse stark voneinander ab, sollte man die Anzahl erhöhen.
Die Rolle der Wahrscheinlichkeitsverteilungen
Das Herzstück jeder Fußballsimulation ist die mathematische Beschreibung dessen, wie Tore fallen. Hier kommt ein statistisches Konzept ins Spiel, das für Prognosemodelle fundamental wichtig ist: die Poisson-Verteilung.
Diese Verteilung wurde im neunzehnten Jahrhundert entwickelt, um seltene Ereignisse zu modellieren, und passt erstaunlich gut auf Tore im Fußball. Ihre Grundannahme ist, dass Ereignisse zufällig und unabhängig voneinander eintreten, mit einer bestimmten durchschnittlichen Rate. Wenn ein Team im Schnitt 1,5 Tore pro Spiel erzielt, gibt die Poisson-Verteilung an, wie wahrscheinlich null, eins, zwei, drei oder mehr Tore sind.
Für ein Team mit einer erwarteten Torzahl von 1,5 sieht die Verteilung ungefähr so aus:
- Null Tore mit etwa zweiundzwanzig Prozent Wahrscheinlichkeit
- Ein Tor mit etwa dreiunddreißig Prozent Wahrscheinlichkeit
- Zwei Tore mit etwa fünfundzwanzig Prozent Wahrscheinlichkeit
- Drei Tore mit etwa dreizehn Prozent Wahrscheinlichkeit
- Vier oder mehr Tore mit etwa sieben Prozent Wahrscheinlichkeit
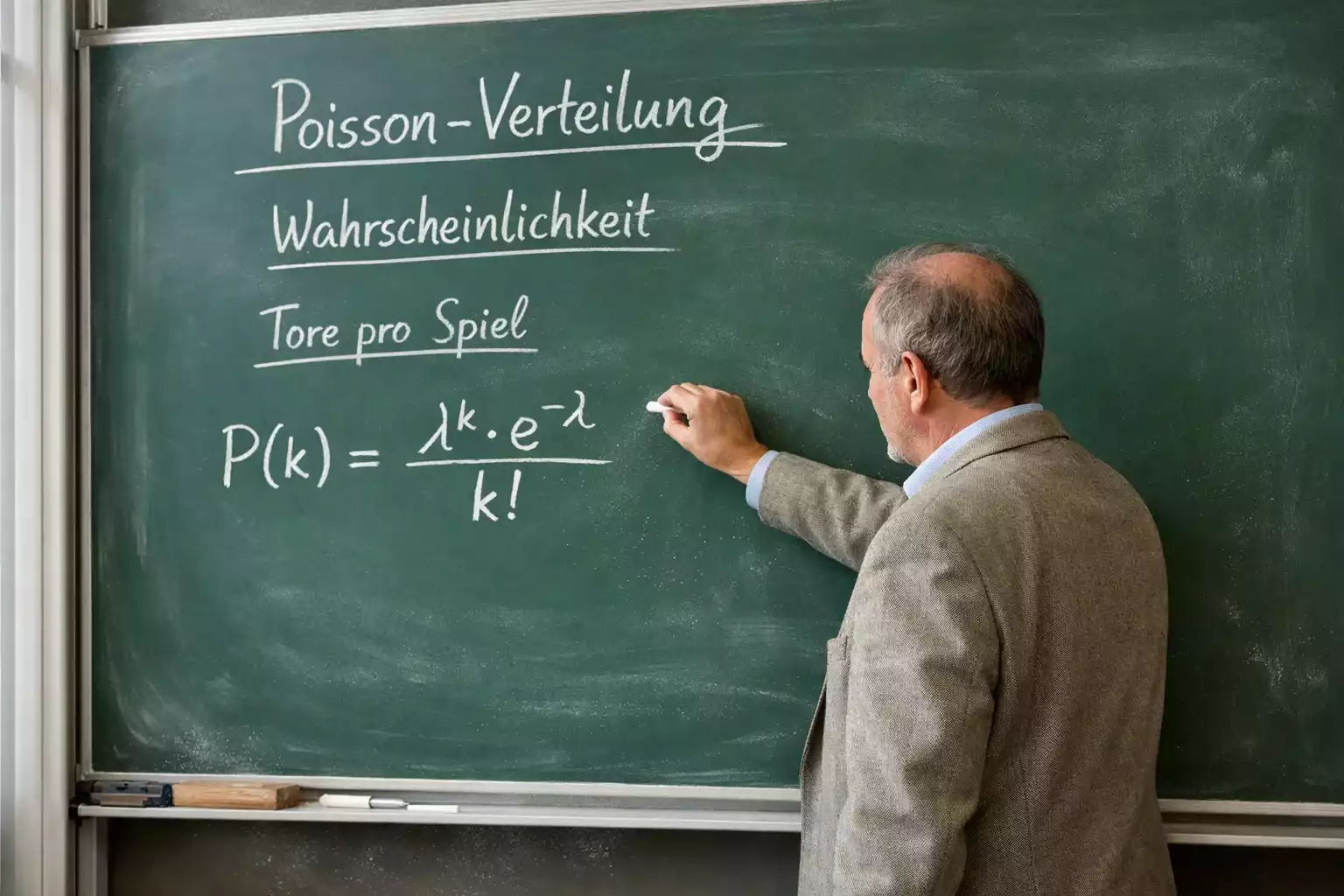
Diese Wahrscheinlichkeiten nutzt die Simulation, um für jedes virtuelle Spiel zu würfeln, wie viele Tore jedes Team erzielt. Die Kombination der beiden Torverteilungen ergibt dann die Ergebniswahrscheinlichkeiten.
Die Poisson-Verteilung ist nicht perfekt. Sie nimmt an, dass jedes Tor unabhängig von den anderen fällt, was nicht ganz stimmt. Wenn ein Team früh in Führung geht, ändert sich oft die Spielweise beider Mannschaften. Außerdem kann sie Extremergebnisse unterschätzen. Spiele, die sechs zu null oder höher ausgehen, sind in der Realität etwas häufiger, als die einfache Poisson-Verteilung vorhersagt.
Fortgeschrittene Modelle verwenden deshalb modifizierte Verteilungen oder kombinieren mehrere Ansätze. Manche berücksichtigen etwa, dass die Varianz der Torzahlen etwas höher ist als bei einer reinen Poisson-Verteilung. Andere modellieren den Spielverlauf detaillierter und berücksichtigen, wie sich das Spielverhalten nach einem Tor ändert.
Komplexere Simulationsansätze
Während die Poisson-basierte Simulation bereits gute Ergebnisse liefert, gehen manche Modelle deutlich weiter. Sie versuchen, nicht nur die Endzahlen zu simulieren, sondern den Spielverlauf selbst.
Ein ereignisbasiertes Simulationsmodell teilt das Spiel in diskrete Zeiteinheiten ein, etwa Minuten. In jeder Minute können verschiedene Ereignisse eintreten: ein Torschuss, eine Ecke, ein Foul, eine Karte. Die Wahrscheinlichkeiten dieser Ereignisse hängen vom Spielstand, der Spielminute und den Eigenschaften der Teams ab.
Dieser Ansatz ermöglicht eine deutlich realistischere Modellierung. Ein Team, das in der achtzigsten Minute knapp zurückliegt, wird anders spielen als eines, das komfortabel führt. Die ereignisbasierte Simulation kann solche Effekte berücksichtigen, während ein einfaches Poisson-Modell sie ignoriert.
Der Preis für diese zusätzliche Komplexität ist ein höherer Rechenaufwand und die Notwendigkeit, viele weitere Parameter zu schätzen. Wie viel wahrscheinlicher ist ein Tor in der Schlussphase, wenn ein Team zurückliegt? Wie verändert sich die Spielweise nach einer Roten Karte? All diese Fragen müssen beantwortet werden, idealerweise mit Daten gestützt.
Ein weiterer fortgeschrittener Ansatz sind agentenbasierte Simulationen. Hier werden nicht nur die Teams, sondern einzelne Spieler modelliert. Jeder Spieler hat bestimmte Eigenschaften wie Geschwindigkeit, Schussgenauigkeit und Passqualität. Das Spiel wird dann als Interaktion dieser Agenten simuliert.
Solche Modelle kommen den tatsächlichen Fußballsimulationen in Videospielen nahe, sind aber für Prognosen kaum verbreitet. Der Grund liegt im Aufwand: Die Kalibrierung solcher Modelle erfordert extrem detaillierte Daten und viel Rechenzeit. Für die meisten praktischen Anwendungen bieten einfachere Modelle ein besseres Verhältnis von Aufwand zu Nutzen.
Saisonsimulationen im Detail
Saisonsimulationen unterscheiden sich von Einzelspielsimulationen nicht nur im Umfang, sondern auch in der Berücksichtigung von Zusammenhängen. Ein gut konzipiertes Modell berücksichtigt, dass die Stärke von Teams sich während einer Saison verändert und dass Ergebnisse nicht unabhängig voneinander sind.
Der erste Aspekt betrifft die zeitliche Entwicklung. Ein Team, das zu Saisonbeginn schwach startet, kann sich durch Trainerwechsel oder Neuzugänge verbessern. Umgekehrt können Verletzungen von Schlüsselspielern oder Formschwächen die Leistung drücken. Gute Saisonsimulationen modellieren diese Dynamik, indem sie nicht von festen Teamstärken ausgehen, sondern diese als veränderlich behandeln.
Der zweite Aspekt betrifft die Korrelation zwischen Spielen. Wenn ein Team überraschend schwach spielt, liegt das vielleicht an einem grundlegenden Problem, etwa einer Verletzungswelle oder taktischen Schwierigkeiten. In diesem Fall ist es wahrscheinlich, dass auch die folgenden Spiele schwach ausfallen. Saisonsimulationen können solche Korrelationen berücksichtigen, indem sie gemeinsame Zufallsfaktoren für mehrere Spiele verwenden.
Ein praktisches Beispiel verdeutlicht die Bedeutung. Angenommen, in der laufenden Saison liegt Bayern München fünf Punkte vor Borussia Dortmund. Eine naive Simulation würde jedes verbleibende Spiel unabhängig simulieren. Eine sophistizierte Simulation berücksichtigt, dass Bayern und Dortmund noch gegeneinander spielen, und dass dieses Spiel besonders wichtig ist. Sie modelliert auch, dass ein Sieg Bayerns in diesem direkten Duell nicht nur drei Punkte bringt, sondern auch Dortmund drei Punkte kostet, ein Sechs-Punkte-Spiel.
Die Ergebnisse von Saisonsimulationen werden oft grafisch dargestellt. Ein Balkendiagramm zeigt für jedes Team die Wahrscheinlichkeitsverteilung der Endplatzierungen. Solche Visualisierungen machen deutlich, dass selbst vermeintlich sichere Saisonziele mit Unsicherheit behaftet sind. Ein Team auf einem Abstiegsplatz hat vielleicht noch zwanzig Prozent Chance auf den Klassenerhalt, während ein Tabellenführer nicht hundertprozentig sicher Meister wird.
Die Grenzen von Simulationsmodellen
So beeindruckend die Möglichkeiten von Spielsimulationen auch sind, es ist wichtig, ihre Grenzen zu kennen. Kein Modell kann die volle Komplexität eines echten Fußballspiels erfassen.
Eine fundamentale Beschränkung ist die Qualität der Eingangsdaten. Die Simulation ist nur so gut wie die Parameter, mit denen sie gefüttert wird. Wenn die geschätzten Torerwartungen falsch sind, werden auch die Simulationsergebnisse falsch sein. Müll rein, Müll raus, wie es im Englischen heißt.

Ein weiteres Problem ist die Modellierung seltener Ereignisse. Rote Karten, Verletzungen während des Spiels, extreme Wetterbedingungen: All das kann ein Spiel entscheidend beeinflussen, tritt aber selten auf. Simulationsmodelle haben Schwierigkeiten, solche Ereignisse angemessen zu berücksichtigen, weil die Datenbasis zu dünn ist.
Die menschliche Psychologie entzieht sich ebenfalls der Modellierung. Ein Team kann in einem wichtigen Spiel über sich hinauswachsen oder unter dem Druck zusammenbrechen. Ein Spieler kann einen schlechten Tag haben, ohne dass es dafür einen erkennbaren Grund gibt. Diese Faktoren sind real, aber kaum zu quantifizieren.
Besonders problematisch wird es bei Ereignissen ohne historischen Präzedenzfall. Die Pandemie-Saison mit Geisterspielen ist ein Beispiel. Die üblichen Heimvorteile galten plötzlich nicht mehr, aber die Modelle hatten keine Daten, um diesen neuen Zustand zu beschreiben. In solchen Situationen müssen die Modellentwickler manuell eingreifen und Annahmen treffen.
Schließlich gibt es das Problem der Überanpassung. Ein Modell kann so komplex werden, dass es die Vergangenheit perfekt erklärt, aber schlecht vorhersagt. Die Kunst liegt darin, das richtige Maß an Komplexität zu finden: komplex genug, um relevante Muster zu erfassen, aber einfach genug, um robust zu bleiben.
Ein praktisches Beispiel: Simulation eines Bundesliga-Spiels
Um die abstrakten Konzepte greifbarer zu machen, gehen wir ein konkretes Beispiel durch. Wir simulieren ein fiktives Spiel zwischen RB Leipzig zu Hause und Eintracht Frankfurt.
Der erste Schritt ist die Bestimmung der Eingangsdaten. Basierend auf den bisherigen Saisondaten und unter Berücksichtigung von Heimvorteil schätzen wir die erwarteten Tore. Leipzig erzielt zu Hause durchschnittlich 2,1 Tore pro Spiel, während Frankfurt auswärts 1,3 Tore kassiert. Die kombinierten und angepassten Werte ergeben eine Torerwartung von etwa 1,9 für Leipzig. Auf der anderen Seite erzielt Frankfurt auswärts etwa 1,2 Tore, und Leipzig kassiert zu Hause 0,9. Die Torerwartung für Frankfurt liegt bei etwa 1,0.
Mit diesen Werten können wir die Poisson-Verteilungen berechnen. Für Leipzig mit einer Erwartung von 1,9 Toren ergibt sich: null Tore mit etwa fünfzehn Prozent, ein Tor mit neunundzwanzig Prozent, zwei Tore mit siebenundzwanzig Prozent, drei Tore mit achtzehn Prozent, vier oder mehr Tore mit elf Prozent. Für Frankfurt mit einer Erwartung von 1,0 Toren: null Tore mit siebenunddreißig Prozent, ein Tor mit siebenunddreißig Prozent, zwei Tore mit achtzehn Prozent, drei oder mehr Tore mit acht Prozent.
Nun starten wir die Simulation. In jedem Durchlauf ziehen wir zufällig aus beiden Verteilungen. Der erste Durchlauf ergibt vielleicht zwei Tore für Leipzig und null für Frankfurt, also ein Zweizunull. Der zweite Durchlauf ergibt eins zu eins. Der dritte zwei zu eins für Leipzig. Und so weiter.
Nach zehntausend Durchläufen haben wir eine Verteilung der Ergebnisse. Leipzig gewinnt in etwa fünfundfünfzig Prozent der Fälle, Unentschieden tritt in etwa zweiundzwanzig Prozent auf, und Frankfurt gewinnt in etwa dreiundzwanzig Prozent. Die Wahrscheinlichkeit für über 2,5 Tore liegt bei etwa fünfundvierzig Prozent. Die Wahrscheinlichkeit, dass beide Teams treffen, bei etwa fünfzig Prozent.
Diese Zahlen können dann mit den Wettquoten verglichen werden, um potenzielle Value-Bets zu identifizieren. Wenn die Buchmacher Leipzig eine Siegwahrscheinlichkeit von fünfzig Prozent zuschreiben, die Simulation aber fünfundfünfzig Prozent ergibt, könnte das eine interessante Wette sein, vorausgesetzt, man vertraut dem Modell.
Die Verbindung von Simulation und maschinellem Lernen
Moderne KI-Systeme für Bundesliga-Prognosen kombinieren oft verschiedene Ansätze. Machine-Learning-Algorithmen werden verwendet, um die Parameter für Simulationen zu bestimmen, und die Simulationsergebnisse fließen wiederum in die Trainingszyklen der Algorithmen ein.
Ein typisches Hybridmodell funktioniert in zwei Stufen. In der ersten Stufe verwendet ein Machine-Learning-Algorithmus wie ein neuronales Netz oder ein Gradient-Boosting-Modell alle verfügbaren Daten, um Teamstärken zu schätzen. Diese Schätzungen berücksichtigen nicht nur historische Ergebnisse, sondern auch detaillierte Spielstatistiken, Verletzungsinformationen und andere relevante Faktoren.
In der zweiten Stufe werden diese geschätzten Teamstärken als Eingabe für eine Monte-Carlo-Simulation verwendet. Die Simulation generiert dann Wahrscheinlichkeitsverteilungen für verschiedene Ausgänge, die nuancierter sind als die direkten Ausgaben des Machine-Learning-Modells.
Der Vorteil dieses Ansatzes liegt in der Kombination der Stärken beider Methoden. Machine Learning ist gut darin, komplexe Muster in Daten zu erkennen und Teamstärken präzise zu schätzen. Simulationen sind gut darin, Unsicherheit zu quantifizieren und Wahrscheinlichkeiten für verschiedene Szenarien zu berechnen.
Ein weiterer Vorteil ist die Transparenz. Während reine Machine-Learning-Modelle oft als Black Box funktionieren, ist die Simulationsstufe verständlicher. Man kann nachvollziehen, wie aus den geschätzten Torerwartungen die Ergebniswahrscheinlichkeiten entstehen.
Wie du Simulationsergebnisse interpretieren solltest
Wenn du KI-basierte Bundesliga-Tipps nutzt, die auf Simulationen basieren, gibt es einige Punkte, die du beachten solltest.
Erstens sind die Wahrscheinlichkeiten Schätzungen, keine Garantien. Eine Siegwahrscheinlichkeit von siebzig Prozent bedeutet, dass das Team in sieben von zehn ähnlichen Situationen gewinnen würde, nicht dass es dieses spezielle Spiel gewinnt. Auch ein Ereignis mit nur zehn Prozent Wahrscheinlichkeit tritt eben in jedem zehnten Fall ein.
Zweitens sind Simulationsergebnisse modellabhängig. Verschiedene Modelle können zu unterschiedlichen Wahrscheinlichkeiten kommen, je nachdem, welche Daten sie nutzen und welche Annahmen sie treffen. Wenn zwei seriöse Quellen deutlich unterschiedliche Wahrscheinlichkeiten angeben, ist das ein Zeichen für echte Unsicherheit.
Drittens solltest du auf die Kalibrierung achten. Ein gutes Modell ist kalibriert, wenn seine Vorhersagen langfristig stimmen. Das bedeutet: Von allen Spielen, denen das Modell eine Siegwahrscheinlichkeit von sechzig Prozent gibt, sollten tatsächlich etwa sechzig Prozent mit einem Sieg enden. Die historische Performance eines Modells ist ein wichtiger Qualitätsindikator.
Viertens sind Simulationen für die Durchschnittssituation optimiert. Extreme Ereignisse wie Rekordergebnisse oder dramatische Aufholjagden sind naturgemäß schwer vorherzusagen. Die Simulation gibt dir einen Erwartungswert, aber die Realität kann immer für Überraschungen sorgen.
Schließlich ersetzen Simulationen nicht das eigene Urteil. Sie sind ein Werkzeug, das dir hilft, Wahrscheinlichkeiten einzuschätzen. Aber die finale Entscheidung, welchem Tipp du vertraust, liegt bei dir.
Die Zukunft von Spielsimulationen
Die Technologie entwickelt sich weiter, und damit auch die Möglichkeiten von Spielsimulationen. Einige Trends zeichnen sich ab, die die nächsten Jahre prägen werden.
Die Integration von Tracking-Daten wird Simulationen realistischer machen. Moderne Tracking-Systeme erfassen die Position jedes Spielers mehrmals pro Sekunde. Diese Daten ermöglichen eine viel detailliertere Modellierung des Spielgeschehens als klassische Event-Daten. Simulationen könnten in Zukunft nicht nur Tore simulieren, sondern auch Spielzüge, Pressing-Situationen und Konter.
Cloud Computing macht aufwendigere Simulationen praktikabel. Was früher Stunden dauerte, kann heute in Sekunden berechnet werden. Das ermöglicht Echtzeitaktualisierungen von Prognosen während eines laufenden Spieltags oder sogar während eines Spiels.
Bayesianische Methoden gewinnen an Bedeutung. Diese statistischen Techniken ermöglichen eine elegantere Behandlung von Unsicherheit. Statt einen festen Parameter anzunehmen, arbeitet man mit Wahrscheinlichkeitsverteilungen über mögliche Parameterwerte. Das führt zu realistischeren Konfidenzintervallen für die Vorhersagen.
Die Kombination von Simulation und Reinforcement Learning ist ein weiteres spannendes Forschungsgebiet. Dabei lernen Algorithmen, Entscheidungen in simulierten Umgebungen zu treffen, ähnlich wie es bei Spielen wie Schach oder Go erfolgreich war. Für Fußballprognosen könnte das bedeuten, dass Modelle nicht nur vorhersagen, sondern auch strategische Empfehlungen geben.
Realistische Erwartungen und gesunde Skepsis

Trotz aller technologischen Fortschritte bleibt Fußball ein Spiel voller Überraschungen. Die beste Simulation der Welt kann nicht vorhersagen, wann ein Ball unglücklich vom Pfosten prallt oder ein Torwart einen unvermuteten Patzer macht.
Die richtige Einstellung zu simulationsbasierten Tipps ist eine Mischung aus Vertrauen und Skepsis. Vertrauen, weil die Methoden auf soliden mathematischen und statistischen Grundlagen basieren. Skepsis, weil kein Modell perfekt ist und die Realität immer komplexer ist als ihre Beschreibung.
Ein Tipp, der auf zehntausend Simulationen basiert, ist fundierter als ein Tipp, der auf Bauchgefühl basiert. Aber er ist nicht unfehlbar. Die Wahrscheinlichkeitsangaben sind Schätzungen, die auf Annahmen beruhen. Wenn diese Annahmen nicht zutreffen, können auch die Vorhersagen daneben liegen.
Für die praktische Nutzung bedeutet das: Nutze Simulationsergebnisse als einen von mehreren Inputs für deine Entscheidung. Vergleiche verschiedene Quellen. Achte auf den Kontext, den ein Modell vielleicht nicht erfasst hat. Und akzeptiere, dass auch eine fundierte Vorhersage mal falsch liegen kann.
Die Faszination des Fußballs liegt gerade in seiner Unberechenbarkeit. Ein Spiel zwischen David und Goliath kann immer überraschend ausgehen. Die Simulation sagt dir, wie wahrscheinlich das ist, aber sie kann es nicht verhindern. Und vielleicht ist das auch gut so, denn perfekte Vorhersehbarkeit würde den Sport um seinen größten Reiz bringen.
Am Ende geht es bei Bundesliga-Tipps um mehr als nur Zahlen und Wahrscheinlichkeiten. Es geht um die Freude am Spiel, die Spannung bis zum Schlusspfiff, das Mitfiebern mit dem eigenen Team. Simulationen können diese Erfahrung bereichern, indem sie ein tieferes Verständnis des Spiels ermöglichen. Aber sie sollten den Spaß nie ersetzen. Ein perfekt kalibriertes Modell, das jeden Ausgang korrekt vorhersagt, wäre technisch beeindruckend, aber sportlich langweilig.
Die Bundesliga lebt von Überraschungen, von Underdogs, die gegen die Favoriten gewinnen, von dramatischen Aufholjagden in der Nachspielzeit, von Spielern, die über sich hinauswachsen. Simulationen können die Wahrscheinlichkeit solcher Ereignisse schätzen, aber sie können sie nicht verhindern. Und darin liegt letztlich der Grund, warum wir Fußball lieben: weil das Unerwartete immer möglich ist.